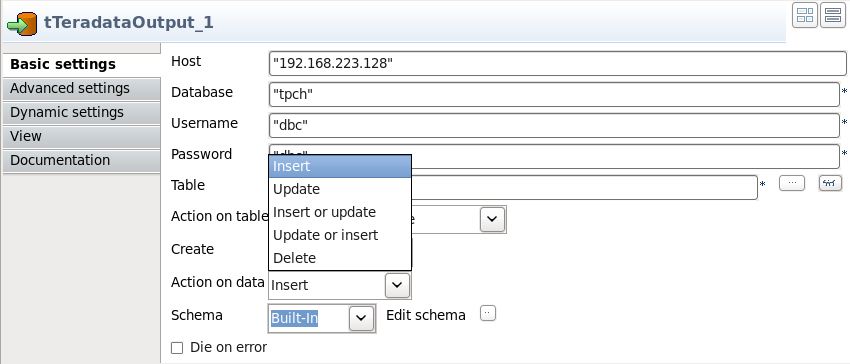
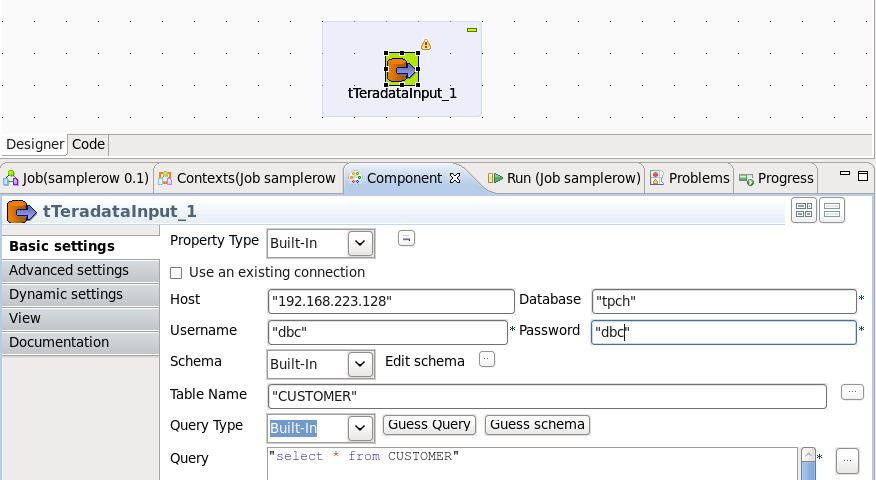
Talend Open studio for big data
provides following components to integrate with hive. You can find these
components in two directories of palette which are as follows
1. Big Data
2. Databases

tHiveconnection: tHiveConnection
is used to establish the connection between Talend and Hive.

For hive
connection we need to know following parameters.
1.1.1
Distribution:
distribution of the hive you are using whether it is HortonsWork, Apache,
cloudera or MapR.
1.1.2
Hive
version: Hive version you are using.
1.1.3
Host: Host address of the hive you are using.
1.1.4 Hadoop Properties: In Hadoop properties we need to give JobTracker URL and Namenode URL for the Hadoop server running.
NOTE:
Before trying for connection make sure that your hadoop server and Hive server is running properly,For checking that hadoop server is running or not use jps command.

tHiveInput: This component is used to extract the data from hive tables on the basis of give Hive query.


tHiveRow: tHiveRow is
used to execute Hive Sql query on the specified database and on each of Talend
flow’s iteration.The specification will be similar as tHiveInput for the connection.

Example for Hive Integration with Talend :

Above scenario is used to read the data from a hive Table.
Step
1. Set the necessary properties for tHiveRow as follows.

Step
2. In tHiveRow we need to set the advance property also because here we are
using resultset object to for extracting the data from hive.

Step
3. Set tParserecordSet properties for the extracting the desirable data from
the resultset.

Step
4. Run the scenario. When you will run the scenario and observe the Hive Thrift
server console then you can observe how hive executes the query by Map reduce
jobs as shown below.

Output
on Talend console:

Thats How Talend Open Studion is integrated with hive. For further queries drop me a mail. Enjoy playing with Hive :)